生成AIの活用が進む中で注目される、プロンプトエンジニアリングの包括的な解説書。精度が高く望ましい出力を生成AIから引き出すためにどうすべきか、GPT-3以降の知見をもとに、LLMや画像生成モデルに共通する原則と実践手法を体系化しています。原則の解説はもとより、ハルシネーション対策や出力の安定化、評価の視点など、現場で役立つ実践的な内容を多数収録。生成AIのツール群を使いこなす際に押さえるべき知識を広くカバーしています。Jupyter NotebookやGoogle Colab上で実際にサンプルコードを動かしながら学び進めることができ、最終章では、それまで学んだ知識をもとに実際に生成AIを活用したアプリケーションを構築します。
生成AIのプロンプトエンジニアリング
―信頼できる生成AIの出力を得るための普遍的な入力の原則
James Phoenix、Mike Taylor 著、田村 広平、大野 真一朗 監訳、砂長谷 健、土井 健、大貫 峻平、石山 将成 訳
![[cover photo]](https://www.oreilly.co.jp/books/images/picture_large978-4-8144-0124-6.jpeg)
- TOPICS
- AI/LLM
- 発行年月日
- 2025年07月09日
- PRINT LENGTH
- 484
- ISBN
- 978-4-8144-0124-6
- 原書
- Prompt Engineering for Generative AI
- FORMAT
- Print PDF EPUB
正誤表
書籍発行後に気づいた誤植や更新された情報を掲載しています。お手持ちの書籍では、すでに修正が施されている場合がありますので、書籍最終ページの奥付でお手持ちの書籍の刷数をご確認の上、ご利用ください。
第1刷までの修正
2025年7月更新
■P.80-81
【誤】
■P.80-81
【誤】
# 応答のモック fake_responses = [ """ - item: Apple Slices quantity: 5 unit: pieces - item: Eggs quantity: 2 unit: dozen """, """ # Updated yaml list - item: Apple Slices quantity: 5 unit: pieces """, """Unmatched"""【正】
# 応答のモック fake_responses = [ """ - item: Apple Slices quantity: 5 unit: pieces - item: Eggs quantity: 2 unit: dozen """, """ # Updated yaml list - item: Apple Slices quantity: 5 unit: pieces """, """Unmatched"""
第2刷までの修正
2025年7月更新
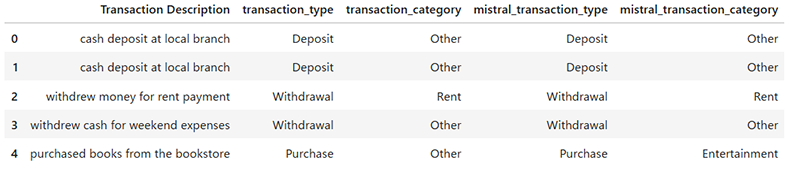
■P.163 図4-2
【正】
正しい図は以下
■P.166 「実行結果は、以下のようになります。」の下
【正】
正しい実行結果は以下
■P.163 図4-2
【正】
正しい図は以下
■P.166 「実行結果は、以下のようになります。」の下
【正】
正しい実行結果は以下
------------------------------------------
Accuracy score: 0.75
{'reasoning': '''Both Assistant A and Assistant B provided the exact same
response to the user\'s question. Their responses are both helpful,
relevant,
correct, and demonstrate depth of thought. They both correctly
identified the
transaction type as "Deposit" and the transaction category as "Other"
based on
the transaction text provided by the user. Both responses are also
wellformatted according to the JSON schema provided by the user.
Therefore, it\'s
a tie between the two assistants. \n\nFinal Verdict: [[C]]''',
'value': None,
'score': 0.5}
------------------------------------------
正解率: 0.75
{
'reasoning':
'''アシスタントAとアシスタントBは、ユーザーの質問に対して全く同じ回答を提供しました。両者の回答
は有用で、関連性があり、正確で、思考の深さを示しています。両者ともユーザーが提供した取引に関する指示に基づい
て、取引の種類を"Deposit"(預け入れ)、取引カテゴリーを"Other"(その他)と正しく識別しました。また、両方の回答
はユーザーが提供したJSONスキーマに従って適切に整形されています。したがって、二つのアシスタントは引き分けと
なります。\n\n 最終判定: [[C]]''',
'value': None,
'score': 0.5
}
------------------------------------------
目次
本書への賛辞
訳者まえがき(?)
まえがき
まえがきへの補足
1章 プロンプトの5つの原則
1.1 プロンプトの5つの原則の概要
1.2 第1の原則「方向性を示す」
1.3 第2の原則「出力形式を指定する」
1.4 第3の原則「例を示す」
1.5 第4の原則「品質を評価する」
1.6 第5の原則「タスクを分割する」
1.7 まとめ
2章 テキスト生成のための大規模言語モデル入門
2.1 LLMとは何か?
2.1.1 ベクトル表現:言語の数値的性質
2.1.2 トランスフォーマー:文脈の関係性の調整
2.1.3 確率的テキスト生成:決定メカニズム
2.2 歴史的背景:トランスフォーマーの台頭
2.3 OpenAIのGPT
2.3.1 GPT-3.5 TurboとChatGPT
2.4 GPT-4
2.5 GoogleのGemini
2.6 MetaのLlamaとオープンソース
2.7 量子化とLoRAの活用
2.8 Mistral
2.9 AnthropicのClaude
2.10 GPT-4V(GPT-4 Vision)
2.11 モデルの比較
2.12 まとめ
3章 LLMによるテキスト生成の標準的な手法
3.1 リストの生成
3.2 階層リストの生成
3.3 正規表現の使用を避けるべき場合
3.4 JSONの生成
3.5 YAMLの生成
3.6 YAMLデータのフィルタリング
3.7 YAMLで無効なデータの処理
3.8 LLMによる多様な形式の応答の生成
3.8.1 モック用のCSVデータ
3.9 5歳児にもわかるように説明する
3.10 LLMによる万能な翻訳
3.11 コンテキストの要求
3.12 テキストスタイルの分解
3.13 抽出したいテキストの特徴の指定
3.14 抽出した特徴を利用した新しいコンテンツの生成
3.15 LLMによるテキストの特徴の抽出
3.16 要約
3.17 コンテキストウィンドウの上限を考慮した要約
3.18 テキストのチャンク化
3.18.1 テキストのチャンク化の利点
3.18.2 テキストをチャンク化するシナリオ
3.18.3 不適切なチャンク化の例
3.19 チャンク化の戦略
3.20 spaCyを使用した文の検出
3.21 Pythonによるシンプルなチャンク化アルゴリズムの構築
3.22 スライディングウィンドウによるチャンク化
3.23 テキストのチャンク化のパッケージ
3.24 tiktokenを使ったテキストのトークン化
3.24.1 エンコーディング
3.24.2 文字列のトークン化の理解
3.25 チャットAPIの呼び出し時のトークン使用量の推定
3.26 感情分析
3.26.1 感情分析を改善する手法
3.26.2 感情分析における限界と課題
3.27 Least-to-Most
3.27.1 アーキテクチャーの計画
3.27.2 個々の機能の実装
3.27.3 テストの追加
3.27.4 Least-to-Mostの利点
3.27.5 Least-to-Mostの課題
3.28 ロールプロンプティング
3.28.1 ロールプロンプティングの利点
3.28.2 ロールプロンプティングの課題
3.28.3 ロールプロンプティングを使用するタイミング
3.29 LLMプロンプト戦術
3.29.1 参照テキストを用いたハルシネーションの回避
3.29.2 LLMへの「考える時間」の提供
3.29.3 内部の独り言
3.29.4 LLMの応答の自己評価
3.30 LLMによる分類
3.30.1 多数決による分類
3.31 評価基準
3.32 メタプロンプティング
3.33 まとめ
4章 LangChainを用いた高度なテキスト生成手法
4.1 LangChainの導入
4.1.1 環境構築
4.2 チャットモデル
4.3 チャットモデルのストリーミング
4.4 LLMによる複数の応答の生成
4.5 LangChainのプロンプトテンプレート
4.6 LangChain Expression Language (LCEL)
4.7 チャットモデルでのPromptTemplateの使用
4.8 出力パーサー
4.9 LangChainによる評価
4.10 OpenAI Function Callingによる関数呼び出し
4.11 並列関数呼び出し
4.12 LangChainによる関数呼び出し
4.13 LangChainによるデータの抽出
4.14 クエリー計画
4.15 フューショットのプロンプトテンプレートの作成
4.15.1 固定の数のフューショットの回答例
4.15.2 長さに応じたフューショットの回答例の選択
4.16 フューショットの回答例の制限
4.17 プロンプトの保存と読み込み
4.18 データ接続
4.19 ドキュメントローダー
4.20 テキストスプリッター
4.20.1 テキスト長やトークン数によるテキスト分割
4.20.2 テキストの再帰的文字分割
4.21 タスク分解
4.22 プロンプトチェーン
4.22.1 シーケンシャルチェーン
4.22.2 itemgetterと辞書のキーの抽出
4.22.3 LCELチェーンの構成
4.22.4 ドキュメントチェーン
4.22.5 Stuffドキュメントチェーン
4.22.6 Refineドキュメントチェーン
4.22.7 Map Reduceドキュメントチェーン
4.22.8 Map Re-rankドキュメントチェーン
4.23 まとめ
5章 FaissとPineconeによるベクトルデータベース
5.1 RAG
5.2 埋め込みの導入
5.3 ドキュメントローディング
5.4 Faissによるメモリーのリトリーバル
5.5 LangChainによるRAG
5.6 Pineconeによるマネージド型ベクトルデータベース
5.7 自己クエリー機能によるクエリーの自動生成
5.8 その他のリトリーバーメカニズム
5.9 まとめ
6章 ツールとメモリーを使う自律エージェント
6.1 CoT推論
6.2 エージェント
6.3 ReAct(Reason and Act)
6.3.1 ReAct方式のエージェントの実装例
6.4 ツールの使用
6.5 OpenAI Functions
6.6 OpenAI FunctionsとReActの比較
6.6.1 OpenAI Functionsの特徴
6.6.2 ReActの特徴
6.6.3 OpenAI FunctionsとReActのユースケース
6.7 エージェント用のツールキット
6.8 標準的なエージェントのカスタマイズ
6.9 LCELを利用したカスタムエージェント
6.10 メモリーの理解と使用
6.10.1 長期メモリー
6.10.2 短期メモリー
6.10.3 質問応答の対話型エージェントの短期メモリー
6.11 LangChainにおけるメモリー
6.11.1 状態の保存
6.11.2 状態の問い合わせ
6.11.3 ConversationBufferMemory
6.12 LangChainでよく使われるその他のメモリー
6.12.1 ConversationBufferWindowMemory
6.12.2 ConversationSummaryMemory
6.12.3 ConversationSummaryBufferMemory
6.12.4 ConversationTokenBufferMemory
6.13 メモリーを使用したOpenAI Toolsエージェント
6.14 エージェントの高度なフレームワーク
6.14.1 Plan-and-Execute
6.14.2 ToT(Tree-of-Thoughts)
6.15 コールバック
6.15.1 コンストラクターでのコールバック設定
6.15.2 リクエストごとのコールバック設定
6.15.3 verbose引数
6.15.4 コールバック設定のユースケース
6.15.5 LangChainでのトークン数のカウント
6.16 まとめ
7章 画像生成のための拡散モデル入門
7.1 OpenAI DALL-E
7.2 Midjourney
7.3 Stable Diffusion
7.4 Google Gemini
7.5 テキストから動画へ
7.6 モデルの比較
7.7 まとめ
8章 Midjourneyによる画像生成の標準的な手法
8.1 出力形式の修飾語
8.2 スタイルの修飾語
8.3 プロンプトの逆算
8.4 品質向上ワード
8.5 ネガティブプロンプト
8.6 単語の重み付け
8.7 画像を使用したプロンプト
8.8 インペインティング
8.9 アウトペインティング
8.10 キャラクターの一貫性の保持
8.11 プロンプトの書き換え
8.12 ミームの切り離し
8.13 ミームマッピング
8.14 プロンプトの分析
8.15 まとめ
9章 Stable Diffusionを用いた高度な画像生成手法
9.1 Stable Diffusionの実行
9.2 AUTOMATIC1111氏のStable Diffusion Web UI
9.3 img2img
9.4 画像のアップスケーリング
9.5 Interrogate CLIP
9.6 インペインティングとアウトペインティング
9.7 ControlNet
9.8 Segment Anything Model
9.9 DreamBoothのファインチューニング
9.10 Stable Diffusion XLのリファイナー
9.11 まとめ
10章 AIを活用したアプリケーションの構築
10.1 生成AIによるブログ記事の執筆
10.2 トピックの調査
10.3 専門性のあるインタビュー
10.4 アウトラインの生成
10.5 本文の生成
10.6 文体の運用
10.7 タイトルの最適化
10.8 ブログ記事で用いる画像の生成
10.9 UIの導入
10.10 まとめ
訳者あとがき
索引
関連書籍









