
図1-1 日本語のテキストマイニングの流れ
日本語におけるテキストマイニングでは、英語のテキストマイニングとは異なる手順が必要となります。日本語では、英語のように文章中の単語が空白で区切られていないために、単語に区切り、各単語の品詞を特定する必要があります。これを形態素解析と言います。1章で文章を個別のトークンに分割するトークン化にあたる部分が形態素解析と考えてもよいかもしれません。形態素解析には、RMeCabというパッケージを利用します。
図1-1 日本語のテキストマイニングの流れ
日本語の文章に対して、形態素解析を行うソフトウェアはいくつかありますが、ここでは無料で使えるMaCabというソフトウェアを使います。MeCabは 京都大学情報学研究科−日本電信電話株式会社コミュニケーション科学基礎研究所共同研究ユニットプロジェクトを通じて開発されたオープンソースの形態素解析エンジンです。Googleの日本語入力開発者の1人である工藤拓氏が作ったソフトウェアで、無料で手軽に形態素解析を行うことができます。MeCabをRから使うには、RMeCabと呼ばれるライブラリが必要になります。RMeCabは、徳島大学の石田基広氏が作ったライブラリで、単にRからMeCabを呼び出すだけでなく、さまざまな便利な関数を含んでいます。RMeCabに関する詳細は、石田氏が自身の著書である『Rによるテキストマイニング入門 第2版』(森北出版)に詳しい使い方も含めてまとめられています。ここでは、RMeCabを使って、日本語の文章に関して、本書の一部の作業を行ってみましょう。
RMeCaBを利用するには、最初にMeCabのインストールが必要になります。
MeCabの公式サイトであるhttp://taku910.github.io/mecab/には、MeCabのダウンロードやインストール方法が説明されています。このサイトに従って、MeCabをインストールしてください。Windows版が必要な方は、バイナリも用意されています。このバイナリには、辞書も含まれているので、インストーラ実行するだけで、容易にインストールすることができます。MacやLinuxの方は、公式サイトからソースをダウンロードして、適当なディレクトリを作成した後、以下の作業をターミナルから行うことで、コンパイル、インストールができます。
% tar zxfv mecab-0.996.tar.gz % cd mecab-0.996 % ./configure % make % make check % sudo make install
MeCabを使用するには、辞書もインストールする必要があります。MeCabの公式サイトには、辞書もダウンロードできるようになっています。ここでは、IPA辞書のインストールのターミナルから行う手順を説明しています。
% tar zxfv mecab-ipadic-2.7.0-20070801.tar.gz % cd mecab-ipadic-2.7.0-20070801 % ./configure % make % sudo make install
いよいよRMeCabのインストールです。RまたはRStudioから、インターネットが接続されている状態で、以下の命令を実行してください。エラーが出なければ、うまくいった証拠です。
install.packages("RMeCab")
library(RMeCab)
それでは、RMeCabを試してみましょう。
RMeCabC("すもももももももものうち")
# [[1]]
# 名詞
# "すもも"
#
# [[2]]
# 助詞
# "も"
#
# [[3]]
# 名詞
# "もも"
#
# [[4]]
# 助詞
# "も"
#
# [[5]]
# 名詞
# "もも"
#
# [[6]]
# 助詞
# "の"
#
# [[7]]
# 名詞
# "うち"
文章が長いと見づらいので、表示を簡単にしてみましょう。
unlist(RMeCabC("すもももももももものうち"))
# 名詞 助詞 名詞 助詞 名詞 助詞 名詞
# "すもも" "も" "もも" "も" "もも" "の" "うち"
文章の単語が分割され、その品詞とともに表示されています。RMeCabC関数は、短い文章についての形態素解析を行う関数です。
それでは、少し長い文章で試してみましょう。本書の1章ではProject Gutenbergからgutenbergrパッケージを用いて、著作権フリーの作品をダウンロードしました。ここでは、日本語の著作権フリーの作品を掲載してある「青空文庫」(http://www.aozora.gr.jp)から、作品をダウンロードして、単語の出現頻度を調べてみましょう。
青空文庫の作品を読み込むには、RMeCabの作者である石田氏の作成したAozoraという便利な関数があります。これは、青空文庫の作品を読み込むだけでなく、ルビを削除してくれます。Aozora関数を利用するには、あらかじめ以下のように入力します。
source("http://rmecab.jp/R/Aozora.R")
「青空文庫」の作品を読み込む準備ができました。今回は、新美南吉作「手袋を買いに」という童話を読んでみます。まず、「青空文庫」のサイトに行き、「手袋を買いに」を探します。そのページの「ファイルのダウンロード」の項目で、テキストファイル(ルビあり)にあるファイル名(ここでは、637_ruby_4095.zip)のリンクを右クリックし、リンクをコピーして、以下のようにAozora関数の引数として読み込みます。
図1-2 青空文庫の「ファイルのダウンロード」
x <- Aozora("http://www.aozora.gr.jp/cards/000121/files/637_ruby_4095.zip")
# example: folder_name <- Aozora('http://www.aozora.gr.jp/
# cards/000081/files/462_ruby_716.zip')
#
#
# URL 'http://www.aozora.gr.jp/cards/000121/files/637_ruby_4095.zip'
# を試しています
# Content type 'application/zip' length 4270 bytes
# ==================================================
# downloaded 4270 bytes
データ操作のためにHadley Wickhamのdplyrパッケージを読み込みます。
library(dplyr)
それでは文書を形態素解析します。実際には、RMeCabパッケージのdocDF関数は、非常に強力でここにある手順のほとんどをdocDF関数だけで処理することができるのですが、ここでは別な関数を使って手順を追って進めていきます。docDF関数の詳細に関しては、ヘルプ等を参照してください。
まず、形態素解析をして、単語の出現頻度を求めます。
glove <- RMeCabFreq(x) # file = ./NORUBY/tebukuroo_kaini2.txt # length = 510 glove %>% head() # Term Info1 Info2 Freq # 1 あ フィラー * 1 # 2 ま フィラー * 1 # 3 いったい 副詞 一般 2 # 4 おっとり 副詞 一般 1 # 5 きっと 副詞 一般 3 # 6 さんざ 副詞 一般 1
ここで、Termは単語(形態素)、Info1は品詞大分類、Info2は品詞細分類、Freqは出現頻度を表しています。次に抽出したい品詞や除外したい品詞についてsubset関数を使って、抽出していきます。以下では、大分類の中から名詞と動詞を抽出し、細分類の中から、数、非自立、接尾にあたる用語を除外しています。
glove2 <- subset(glove, Info1 %in% c("名詞", "動詞"))
glove3 <- subset(glove2, !Info2 %in% c("数", "非自立", "接尾"))
glove3 %>% head()
# Term Info1 Info2 Freq
# 103 あう 動詞 自立 1
# 104 あきれる 動詞 自立 1
# 105 あける 動詞 自立 1
# 106 ある 動詞 自立 3
# 107 あわてふためく 動詞 自立 1
# 108 いう 動詞 自立 3
次に単語の出現頻度順にソートします。
glove4 <- glove3[order(glove3$Freq, decreasing = T),] glove4 %>% head() # Term Info1 Info2 Freq # 330 狐 名詞 一般 51 # 127 する 動詞 自立 28 # 310 手 名詞 一般 27 # 285 人間 名詞 一般 17 # 211 言う 動詞 自立 15 # 322 母さん 名詞 一般 14
さて、これらの単語の出現頻度をもとにグラフを描いてみましょう。ここでは、出現頻度6以上の単語についてのグラフを描いています。
glove4 %>%
filter(Freq >=6) %>%
mutate(Term=reorder(Term, Freq)) %>%
ggplot(aes(Term,Freq)) +
geom_col() +
theme_gray (base_family = "IPAMincho") +
coord_flip()
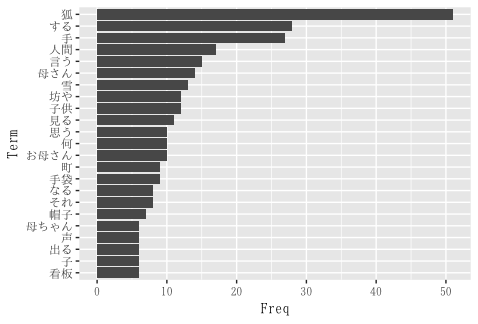
図1-3 「手袋を買いに」の単語の出現頻度
次にこのデータをもとにワードクラウドを作ってみましょう。ワードクラウドを作るには、2章で紹介したwordcloudパッケージを利用します。日本語を表示するには、familyにフォント名を指定します。
library(wordcloud) wordcloud(glove4$Term, glove4$Freq, min.freq=4, color=brewer.pal(8, "Dark2"), family="IPAMincho")

図1-4 「手袋を買いに」のワードクラウド
4章で学んだnグラムやバイグラムをもとに形態素解析がうまくいっているかどうかを確かめてみましょう。
今度は同じ新美南吉の作品の「ごんぎつね」を読み込んでみます。
X <- Aozora("http://www.aozora.gr.jp/cards/000121/files/628_ruby_649.zip")
# example: folder_name <- Aozora('http://www.aozora.gr.jp/
# cards/000081/files/462_ruby_716.zip')
#
#
# URL 'http://www.aozora.gr.jp/cards/000121/files/628_ruby_649.zip'
# を試しています
# Content type 'application/zip' length 5508 bytes
# ==================================================
# downloaded 5508 bytes
「手袋を買いに」と同じ手順で、形態素解析を行い、ワードクラウドを作ってみます。
gon <- RMeCabFreq(x)
gon2 <- subset(gon, Info1 %in% c("名詞", "動詞"))
gon3 <- subset(gon2, !Info2 %in% c("数", "非自立", "接尾"))
gon4 <- gon3[order(gon3$Freq, decreasing = T),]
library(wordcloud)
wordcloud(gon4$Term, gon4$Freq, min.freq=4, color=brewer.pal(8, "Dark2"), family="IPAMincho")

図1-5 「ごんぎつね」の名詞と動詞のワードクラウド
あれ、おかしいですね。「ごんぎつね」の主人公は、狐の「ごん」と兵十でした。「兵」というのは、「兵十」を意味しているのでしょうか。4章で学んだバイグラムを用いて、名詞の共起関係を分析してみます。
ngram <- NgramDF(x, type=1, pos=c("名詞"), N=2)
# file = ./NORUBY/gongitsune2.txt Ngram = 2
ngram %>% head()
# Ngram1 Ngram2 Freq
# 1 あかり 坊主 1
# 2 あくる日 栗 1
# 3 あした 栗 1
# 4 あたり すすき 1
# 5 あたり 村 1
# 6 あと ほんと 1
共起関係の出現頻度順に並べてみると、確かに「兵十」という固有名詞をMeCabが2つの名詞として分割しているのがわかります。「加助」という登場人物の固有名詞も分割されているのがわかります。
ngram2<-ngram[order(ngram$Freq,decreasing = T),] ngram2 %>% head() # Ngram1 Ngram2 Freq # 360 兵 十 38 # 364 加 助 7 # 390 十 家 7 # 441 家 中 5 # 147 つぎ 日 4 # 163 の ん 4
バイグラムの出現頻度の高いものについて、有向グラフでその関係を表してみましょう。ここでは、igraphライブラリを使います。
ngram2 <- subset(ngram2, Freq>=3) library(igraph) graph <- graph.data.frame(ngram2) plot(graph, vertex.label=V(graph)$name, vertex.size=15)
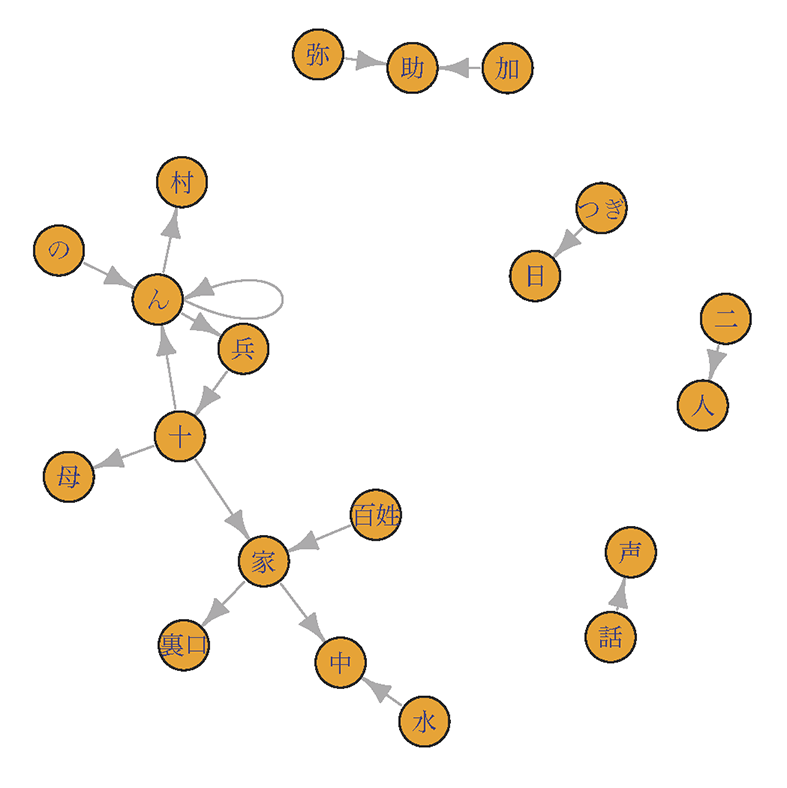
図1-6 「ごんぎつね」の名詞のバイグラム
やはりおかしいことがわかりました。
日本語のテキストマイニングにおいては、RMeCabによる形態素解析が有効です。英語におけるトークン化のプロセスをこれに代えて考えることで同様の処理を行うことができます。また、ggplot2ライブラリなどを利用したグラフなどの表示に関しては、標準では日本語フォントが対応していない場合もありますので、指定して表示する必要があります。
参考文献:石田基弘著、「Rによるテキストマイニング入門」(第2版)、森北出版、2017