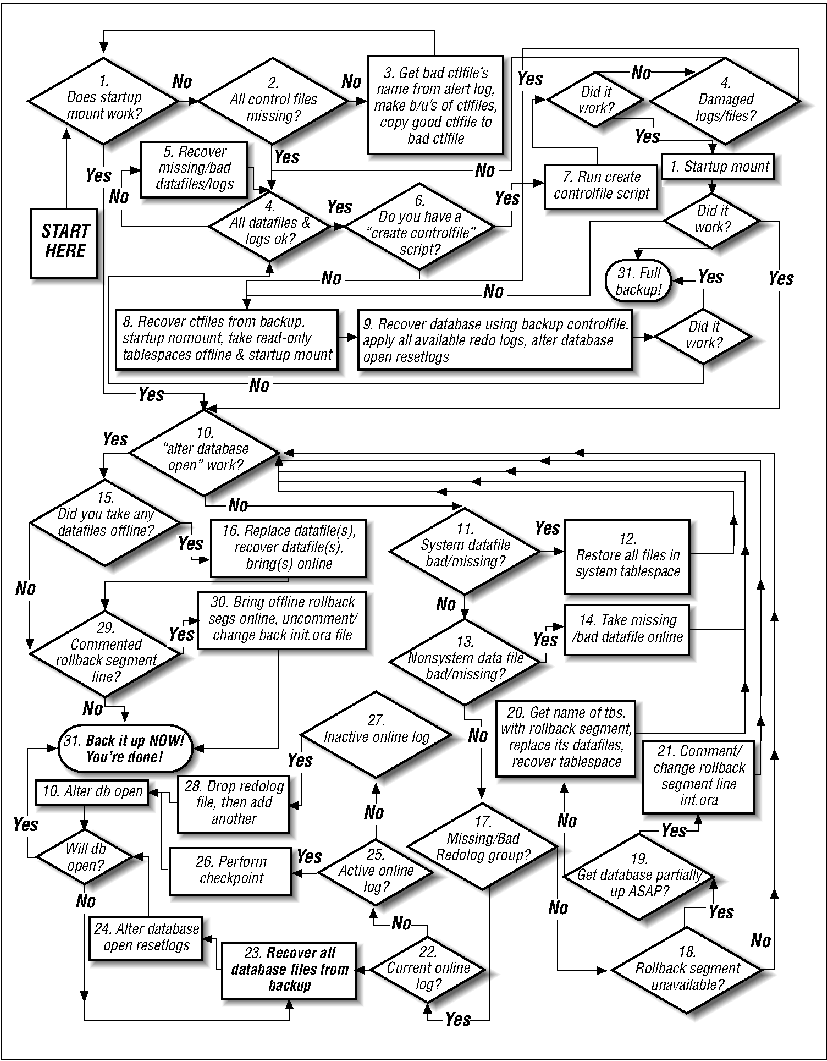
Since an Oracle database consists of several interrelated parts, recovering such a database is done through a process of elimination. Identify which pieces work, then recover the pieces that don't work. The following recovery guidefollows that logic and works regardless of the chosen backup method. It consists of a flowchart and a procedure whose numbered steps correspond to the elements in the flowchart.
The first step in verifying the condition of an Oracle database is to attempt to mount it. This works because mounting a database (without opening it) reads the control files but does not open the data files. If the control files are mirrored, Oracle attempts to open each of the control files that are listed in the initORACLE_SID.ora file. If any of them is damaged, the mount fails.
To mount a database, simply run svrmgrl, connect to the database, and enter startup mount.
SVRMGR > connect internal;
Connected.
SVRMGR > startup mount;
Statement processed.
ORACLE instance started.
Total System Global Area 5130648 bytes
Fixed Size 44924 bytes
Variable Size 4151836 bytes
Database Buffers 409600 bytes
Redo Buffers 524288 bytes
Database mounted.
Total System Global Area 5130648 bytes
Fixed Size 44924 bytes
Variable Size 4151836 bytes
Database Buffer to s 409600 bytes
Redo Buffers 524288 bytes
ORACLE instance started.
ORA-00205: error in identifying controlfile, check alert log for more info
Don't panic if the attempt to mount the database fails. Control files are easily restored if they were mirrored, and can even be rebuilt from scratch if necessary. The first important piece of information is that one or more control files are missing.
Unfortunately, since Oracle aborts the mount at the first failure it encounters, it could be missing one, two, or all of the control files, but so far you know only about the first missing file. So, before embarking on a course of action, determine the severity of the problem. In order to do that, do a little research.
First, determine the names of all of the control files. Do that by looking at the configORACLE_SID.ora file next to the word control files. It looks something like this:
/db/Oracle/b/oradata/crash/control02.ctl,
/db/Oracle/c/oradata/crash/control03.ctl)
alter database mount exclusive
Sat Feb 21 13:46:20 1998
ORA-00202: controlfile: '/db/a/oradata/crash/control01.ctl'
ORA-27037: unable to obtain file status
SVR4 Error: 2: No such file or directory
The damaged file is missing, and at least one other file is present
If the file that Oracle is complaining about is either missing or appears to have a different date and time than the other control files, this will be easy. Simply copy another one of the mirrored copies of the control file to the damaged control file's name and location. (The details of this procedure are below.) Once this is done, just attempt to mount the database again.
alter database mount exclusive
Sat Feb 21 13:46:20 1998
ORA-00202: controlfile: '/db/a/oradata/crash/control01.ctl'
ORA-27037: unable to obtain file status
SVR4 Error: 2: No such file or directory
It's possible that there may be no known good control file, which is what would happen if the remaining control files have different dates and/or sizes. If this is the case, it's probably best to use the "create controlfile" script.
First, make backup copies of all the files:
$ cp /b/control2.ctl /b/control2.ctl.sav
$ cp /c/control3.ctl /c/control3.ctl.sav
$ cp /a/control1.ctl /c/control3.ctl
SVRMGR > connect internal;
Connected.
SVRMGR > startup mount
Sat Feb 21 15:43:21 1998
alter database mount exclusive
Sat Feb 21 15:43:22 1998
ORA-00202: controlfile: '/a/control3.ctl'
ORA-27037: unable to obtain file status
$ cp /b/control2.ctl /a/control3.ctl
ORACLE instance started.
Total System Global Area 5130648 bytes
Fixed Size 44924 bytes
Variable Size 4151836 bytes
Database Buffers 409600 bytes
Redo Buffers 524288 bytes
Database mounted.
The reason that this is the case is that the rebuild process looks at each data file as it is rebuilding the control file. Each data file contains a System Change Number (SCN) that corresponds to a certain online redo log. If a data file shows that it has an SCN that is more recent than the online redo logs that are available, the control file rebuild process will abort.
If one or more of the data files or online redo logs are definitely damaged, follow all the instructions below to see if there are any other damaged files. (A little extra effort now will save a lot of frustration later.) If it's possible that all the data files and online redo logs are okay, another option would be to skip this step and try to recreate the control file now. (An unsuccessful attempt at this will not cause any harm.) If it fails, return to this step. If there is plenty of time, go ahead and perform this step first.
SVRMGR > select name from v$datafile;
(Example output below)
SVRMGR > select group#, member from v$logfile;
(Example output below)
NAME
--------------------------------------------------------------------------------
/db/Oracle/a/oradata/crash/system01.dbf
/db/Oracle/a/oradata/crash/rbs01.dbf
/db/Oracle/a/oradata/crash/temp01.dbf
/db/Oracle/a/oradata/crash/tools01.dbf
/db/Oracle/a/oradata/crash/users01.dbf
/db/Oracle/a/oradata/crash/test01.dbf
6 rows selected.
SVRMGR > select group#, member from v$logfile;
MEMBER
--------------------------------------------------------------------------------
1 /db/Oracle/a/oradata/crash/redocrash01.log
3 /db/Oracle/c/oradata/crash/redocrash03.log
2 /db/Oracle/b/oradata/crash/redocrash02.log
1 /db/Oracle/b/oradata/crash/redocrash01.log
2 /db/Oracle/a/oradata/crash/redocrash03.log
3 /db/Oracle/c/oradata/crash/redocrash02.log
6 rows selected.
SVRMGR >
Redo log files, however, are a little different. Each redo log file within a log group should have the same modification time. For example, the output of the example command above shows that /db/Oracle/a/oradata/crash/redocrash01.log and /db/Oracle/a/oradata/crash/redocrash01.log are in log group one. They should have the same modification time and size. The same should be true for groups two and three. There are a couple of possible scenarios:
One or more log groups has at least one good and one damaged log
$ cp /db/Oracle/a/oradata/crash/redocrash01.log \
/db/Oracle/a/oradata/crash/redocrash01.log
If all the redo logs in at least one group are damaged, and all the control files are damaged, proceed to Steps 23 and 24.
If the redo logs are all right, but all the control files are missing, proceed to Step 6.
If the database will not open for some other reason, proceed to Step 10.
user_dump_dest = /db/Oracle/admin/crash/udump
$ cd /db/Oracle/admin/crash/udump ; grep 'CREATE CONTROLFILE' * \
|awk -F: '{print $1}'|xargs ls -ltr
-rw-r----- 1 Oracle dba 3399 Oct 26 11:25 crash_ora_617.trc
-rw-r----- 1 Oracle dba 3399 Oct 26 11:25 crash_ora_617.trc
-rw-r----- 1 Oracle dba 1179 Oct 26 11:29 crash_ora_661.trc
First, find the trace file that contains the script. The instructions on how to do that are in Step 6. Once you find it, copy it to another filename, such as rebuild.sql. Edit the file, deleting everything above the phrase # The following commands will create, and anything after the last SQL command. The file should then look something like the one in Figure D:
# to open the database.
# Data used by the recovery manager will be lost. Additional logs may
# be required for media recovery of offline data files. Use this
# only if the current version of all online logs are available.
STARTUP NOMOUNT
CREATE CONTROLFILE REUSE DATABASE "CRASH" NORESETLOGS ARCHIVELOG
MAXLOGFILES 32
MAXLOGMEMBERS 2
MAXDATAFILES 30
MAXINSTANCES 8
MAXLOGHISTORY 843
LOGFILE
GROUP 1 '/db/a/oradata/crash/redocrash01.log' SIZE 500K,
GROUP 2 '/db/b/oradata/crash/redocrash02.log' SIZE 500K,
GROUP 3 '/db/c/oradata/crash/redocrash03.log' SIZE 500K
DATAFILE
'/db/a/oradata/crash/system01.dbf',
'/db/a/oradata/crash/rbs01.dbf',
'/db/a/oradata/crash/temp01.dbf',
'/db/a/oradata/crash/tools01.dbf',
'/db/a/oradata/crash/users01.dbf'
;
# Recovery is required if any of the data files are restored backups,
# or if the last shutdown was not normal or immediate.
RECOVER DATABASE
# All logs need archiving and a log switch is needed.
ALTER SYSTEM ARCHIVE LOG ALL;
# Database can now be opened normally.
ALTER DATABASE OPEN;
# Files in read only tablespaces are now named.
ALTER DATABASE RENAME FILE 'MISSING00006'
TO '/db/a/oradata/crash/test01.dbf';
# Online the files in read only tablespaces.
ALTER TABLESPACE "TEST" ONLINE;
But I didn't mirror my control files or my online redo logs
Follow the steps below, starting with restoring the control files from backup. Chances are that the database files will need to be restored as well. This is because one cannot use a control file that is older than the most recent database file. (Oracle will complain and abort if this happens.) To find out if the control file is newer than the data files, try the following steps without overwriting the database files and see what happens.
Restore control files from backup
control_files = (/db/Oracle/a/oradata/crash/control01.ctl,
/db/Oracle/b/oradata/crash/control02.ctl,
/db/Oracle/c/oradata/crash/control03.ctl)
Again, this backup control file must be more recent than the most recent database file in the instance. If this isn't the case, Oracle will complain.
SVRMGR > connect internal;
Connected.
SVRMGR > startup mount;
Statement processed.
SVRMGR > quit
SVRMGR > connect internal;
Connected.
SVRMGR > select enabled, name
from v$data file;
Statement processed.
SVRMGR > quit
SVRMGR > connect internal;
Connected.
SVRMGR > alter database data file
'filename' offline;
Statement processed.
SVRMGR > quit
Attempt to recover database normally
Since recovering the database with a backup control file requires the alter database open resetlogs option, it never hurts to try recovering the database normally first:
SVRMGR > connect internal;
Connected.
SVRMGR > recover database;
ORA-00283: Recover session cancelled due to errors
...
ORA-01207: file is more recent than controlfile - old controlfile
Attempt to recover the database using the following command on the mounted, closed database:
SVRMGR > connect internal;
Connected.
SVRMGR > recover database using backup controlfile
ORA-00289: suggestion : /db/Oracle/admin/crash/arch/arch.log1_494.dbf
ORA-00280: change 38666 for thread 1 is in sequence #494
If Oracle complains, there are probably some missing or corrupted data files. If so, return to Steps 4 and 5. Once any missing or corrupted data files are restored, return to this step and attempt to recover the database again.
Sometimes one can get in a catch-22 when recovering databases, where Oracle is complaining about data files being newer than the control file. The only way to get around this is to use a backup version of the data files that is older than the backup version of the control file. Media recovery will roll forward any changes that this older file is missing.
Oracle will request all archived redo logs since the time of the oldest restored data file. For example, if the backup that was used to restore the data files was from three days ago, Oracle will need all archived redo logs created since then. Also, the first log file that it asks for is the oldest log file that it wants.
The most efficient way to roll through the archived redo logs is to have all of them sitting uncompressed in the directory that it suggests as the location of the first file. If this is the case, simply enter auto at the prompt. Otherwise, specify alternate locations or hit enter as it asks for each one, giving time to compress or remove the files that it no longer needs.
Apply online redo logs if they are available
If it is able to do so, Oracle will automatically roll through all the archived redo logs and the online redo log. Then it says, "Media recovery complete."
However, once Oracle rolls through all the archived redo logs, it may prompt for the online redo log. It does this by prompting for an archived redo log with a number that is higher than the most recent archived redo log available. This means that it is looking for the online redo log. Try answering its prompt with the names of the online redo log files that you have. Unfortunately, as soon as you give it a name it doesn't like, it will make you start the recover database using backup controlfile command again.
For example, suppose that you have the following three online redo logs:
/oracle/data/redolog02.dbf
/oracle/data/redolog03.dbf
ORA-00334: archive log: '/oracle/data/redolog01.dbf'
Media recovery complete.
Alter database open resetlogs
Once the media recovery is complete, the next step is to open the database. As mentioned earlier, when recovering the database using a backup control file, it must be opened with the resetlogs option. Do this by entering:
SVRMGR > connect internal;
Connected.
SVRMGR > alter database open resetlogs;
SVRMGR > quit
If the database did open successfully, perform a backup of the entire database immediately -- preferably a cold one. Congratulations! You're done!
If the startup mount worked, this is actually only the second step that you will perform. Mounting the database only checks the presence and consistency of the control files. If that works, opening the database is the next step. Doing so will check the presence and consistency of all data files, online redo log files, and any rollback segments. To open the database, run the following command on the mounted, closed database:
SVRMGR > connect internal;
Connected.
SVRMGR > alter database open;
SVRMGR > quit
If the database did open, proceed to
Step 15.
Missing data file
ORA-01110: data file 1: '/db/Oracle/a/oradata/crash/system01.dbf'
ORA-01110: data file 1: '/db/Oracle/a/oradata/crash/system01.dbf'
ORA-01110: data file 1: '/db/Oracle/a/oradata/crash/system01.dbf'
ORA-01200: actual file size of 1279 is smaller than correct size of 40960 blocks
ORA-00313: open failed for members of log group 2 of thread 1
ORA-00312: online log 2 thread 1: '/db/Oracle/b/oradata/crash/redocrash02.log'
ORA-00312: online log 2 thread 1: '/db/Oracle/a/oradata/crash/redocrash03.log'
ORA-00312: online log 2 thread 1: '/db/Oracle/b/oradata/crash/redocrash02.log'
ORA-00312: online log 2 thread 1: '/db/Oracle/a/oradata/crash/redocrash03.log'
Cannot open database if all rollback segments are not available.
A damaged data file is actually very easy to recover from. This is a good thing, because this will occur more often than any other problem. Remember that there is only one copy of each data file, unlike online redo logs and control files that can be mirrored. So, statistically speaking, it's easier to lose one data file than to lose all mirrored copies of a log group or all mirrored copies of the control file.
Oracle also has the ability to recover parts of the database while other parts of the database are brought online. Unfortunately, this helps only if a partially functioning database is of any use to the users in your environment. Therefore, a database that is completely worthless unless all tables are available will not benefit from the partial online restore feature. However, if the users can use one part of the database while the damaged files are being recovered, this feature may help to save face by allowing at least partial functionality during an outage.
There are three types of data files as far as recovery is concerned:
If all members of a log group are damaged, there is a great potential for data loss. The entire database may have to be restored, depending on the status of the log group that was damaged, and the results of some attempts at fixing it. This may seem like a broken record, but this is why mirroring the log groups is so important.
Since Oracle has to open the data files that contain this rollback segment before it can verify that the rollback segment is available, this error will not occur unless a data file has been taken offline. If Oracle encounters a damaged data file (whether or not it contains a rollback segment), it will complain about that data file and abort the attempt to open the database.
Remember that a rollback segment is a special part of a tablespace that stores rollback information. Rollback information is needed in order to undo (or rollback) an uncommitted transaction. Since a crashed database will almost always contain uncommitted transactions, recovering a database with a damaged rollback segment is a little tricky. As previously mentioned, a damaged data file may be taken offline, but Oracle will not open the database without the rollback segment.
The strategy for dealing with this is to make Oracle believe that the rollback segment doesn't exist. That will allow the database to be brought online. However, there will be transactions that need to be rolled back that require this rollback segment. Since Oracle believes this rollback segment is no longer available, these rollbacks cannot occur. This means that the database may be online, but portions of it will not be available.
For example, suppose that we created a table called data1 inside tablespace USERS. Tablespace USERS contains the data file /db/oracle/a/oradata/crash/users01.dbf. Unfortunately, the database crashed before this transaction was committed, and the data file that contains the rollback segment for this transaction was destroyed. In the process of recovering this database, we took that data file offline, convinced Oracle that the rollback segment it contained was not needed, and opened the database. If we run the command select * from data1, we will receive the error shown in Figure F:
SVRMGR > connect internal;
Connected.
SVRMGR > select * from data1;
C1
------------
ORA-00376: file 7 cannot be read at this time
ORA-01110: datafile 7: '/db/oracle/a/oradata/crash/users01.dbf'
Be aware, therefore, that if you bring a database online without all of its rollback segments, the database may be online -- but it probably will not be fully functional.
Remember that Oracle will stop attempting to open the database as soon as it encounters an error with one file. This means, of course, that there could be other files that are damaged. If there is at least one damaged data file, now is a good time to check and see if there are other files that are damaged.
How media recovery works
If any data files are restored from backup, the svrmgr recover command will be needed. This command uses the archived and online redo logs to "redo" any transactions that have occurred since the time that the backup of a data file was taken. You can recover a complete database, a tablespace, or a data file by issuing the commands recover database, recover tablespace tablespace_name and recover data file data file_name, respectively. These commands are issued inside a svrmgr shell. For example:
SVRMGR > connect internal
SVRMGR > startup mount
SVRMGR > recover datafile '/db/Oracle/a/oradata/crash/datafile01.dbf'
This recovery can work in a number of ways. After receiving the recover command, Oracle prompts for the name and location of the first archived redo log that it needs. If that log, and all logs that have been made sinse that log, are online, uncompressed, and in their original location, enter the word AUTO. This tells Oracle to assume that all files that it needs are online. It can therefore automatically roll through each log that it needs.
In order to do this, all files that Oracle will need must be online. First, get the name of the oldest file, since that it is the first file it will need. That file name is displayed immediately after issuing the recover command:
ORA-00289: suggestion : /db/Oracle/admin/crash/arch/arch.log1_481.dbf
ORA-00280: change 18499 for thread 1 is in sequence #481
Specify log: {<RET>=suggested | filename | AUTO | CANCEL}
If there isn't enough space for all of the archived redo logs to be uncompressed, a little creativity may be required. Uncompress as many as possible, and then hit enter each time it suggests the next file. (Hitting enter tells Oracle that the file that it is suggesting is available. If it finds that it is not available, it prompts for the same file again.) Once it has finished with one archive log, compress that log, and uncompress a newer log, since it will be needed it shortly. (Obviously, a second window is required, and a third window wouldn't hurt!)
At some point, it may ask for an archived redo log that is not available. This could mean some of the archived redo logs or online redo logs are damaged. If the file cannot be located or restored, enter CANCEL.
More detail on media recovery is available in Oracle's documentation.
If the damaged file is part of the SYSTEM tablespace, an offline recovery is required. All other missing data files can be recovered with the database online. Unfortunately, Oracle only complains that the data file is missing -- without saying what kind of data file it is. Fortunately, even if Oracle is down, there is an easy way to determine which files belong to the SYSTEM tablespace. (Finding out if the data file contains a rollback segment is a little more difficult, but it is still possible.) To find out which data files are in the SYSTEM tablespace, run the following command on the mounted, closed database:
SVRMGR > connect internal;
Connected.
SVRMGR > select name from v$datafile where status = 'SYSTEM' ;
NAME
--------------------------------------------------------------------------------
/db/oracle/a/oradata/crash/system01.dbf
1 row selected.
Unlike other tablespaces, the SYSTEM tablespace must be available in order to open the database. Therefore, if any members of the system tablespace are damaged, they must be restored now. Before doing this, make sure that the database is not open. (It is okay if it is mounted.) To make sure, run the following command on the mounted, closed database:
SVRMGR > connect internal;
Connected.
SVRMGR > select status from v$instance;
STATUS
-------
MOUNTED
1 row selected.
If the database is not open, restore the damaged files from the most recent backup available. Once all damaged files in the system tablespace are restored, run the following command on the mounted, closed database:
SVRMGR > connect internal;
Connected.
SVRMGR > recover tablespace system;
SVRMGR > media recovery complete
So far, we have mounted the database, which proves that the control files are okay. It may have taken some effort if one or more of the control files were damaged, but it succeeded. We have also verified that the SYSTEM tablespace is intact, even if it required a restore and recovery. Most of the rest of this procedure concentrates on disabling damaged parts of the database so that it may be brought online as soon as possible. The process of elimination will identify all damaged data files once the database is opened successfully. They can then be easily restored.
To open a database with a damaged, non-system data file, take the data file offline. (If the file that is taken offline is part of a tablespace that contains rollback segments, there will be one other step, but we'll cross that bridge when we come to it.)
If this instance is operating in ARCHIVELOG mode, just take the data file offline. It can later be restored and recovered after the instance has been brought online. The command to do this is:
SVRMGR > connect internal;
Connected.
SVRMGR > alter database datafile 'filename' offline;
SVRMGR > connect internal;
Connected.
SVRMGR > alter database datafile 'filename' offline drop;
First find out which data files were taken offline. To do this, run the following command:
SVRMGR > connect internal;
Connected.
SVRMGR > select name from v$datafile where status = 'OFFLINE' ;
NAME
------------------
/db/oracle/a/oradata/crash/temp01.dbf
/db/oracle/a/oradata/crash/tools01.dbf
/db/oracle/a/oradata/crash/users01.dbf
Once the names of the data files that need to be restored are determined, restore them from the latest available backup. Once they are restored, recovery within Oracle can be accomplished in three different ways. These ways vary greatly in complexity and flexibility. Examine the following three media recovery methods and choose whichever one is best for you.
Datafile recovery
If there is a small number of data files to recover, this may be the easiest option. As each file is restored, issue the recover data file command against it and then bring it online:
SVRMGR > connect internal;
Connected.
SVRMGR > recover datafile 'datafile_name' ;
Statement processed.
SVRMGR > alter database datafile
'datafile_name' online ;
Statement processed.
Tablespace recovery
This method is the hardest of all methods, but it may work faster than the previous method if there are several damaged data files within a tablespace. If forced to leave the partially functional database open while recovering the damaged data files, and there are several of them to recover, this is probably the best option.
First find out the names of all data files, and the tablespace to which they belong. Since the database is now open, this can be done in one step, demonstrated in Figure G:
SVRMGR > connect internal;
Connected.
SVRMGR > select file_name, tablespace_name
from dba_data_files;
Statement processed.
FILE_NAME
TABLESPACE_NAME
--------------------------------------------------------------------------------
------------------------------
/db/oracle/a/oradata/crash/users01.dbf
USERS
/db/oracle/a/oradata/crash/tools01.dbf
TOOLS
/db/oracle/a/oradata/crash/temp01.dbf
TEMP
/db/oracle/a/oradata/crash/rbs01.dbf
RBS
/db/oracle/a/oradata/crash/system01.dbf
SYSTEM
/db/oracle/a/oradata/crash/test01.dbf
TEST
connect internal;
select file_name, tablespace_name from dba_data_files;
quit;
EOF
$ grep '^/' /tmp/files.txt
/db/oracle/a/oradata/crash/rbs01.dbf RBS
/db/oracle/a/oradata/crash/system01.dbf SYSTEM
/db/oracle/a/oradata/crash/temp01.dbf TEMP
/db/oracle/a/oradata/crash/test01.dbf TEST
/db/oracle/a/oradata/crash/tools01.dbf TOOLS
/db/oracle/a/oradata/crash/users01.dbf USERS
Once all of the data files are restored, and the names of all the tablespaces that contain these data files have been determined, issue the recover tablespace command against each of those tablespaces. Before doing so, however, each of those tablespaces must be taken offline, as shown in Figure I.
SVRMGR > connect internal;
Connected.
SVRMGR > alter tablespace tablespace_name1 offline;
Statement processed.
SVRMGR > recover tablespace tablespace_name1 ;
ORA-00279: change 18499 generated at 02/21/98 11:49:56 needed for thread 1
ORA-00289: suggestion : /db/Oracle/admin/crash/arch/arch.log1_481.dbf
ORA-00280: change 18499 for thread 1 is in sequence #481
Specify log: {<RET>=suggested | filename | AUTO | CANCEL}
Auto
Log applied
Media Recovery Complete
SVRMGR > alter tablespace tablespace_name1 online;
Statement processed.
SVRMGR > alter tablespace tablespace_name2 offline;
Statement processed.
SVRMGR > recover tablespace tablespace_name2 ;
ORA-00279: change 18499 generated at 02/21/98 11:49:56 needed for thread 1
ORA-00289: suggestion : /db/Oracle/admin/crash/arch/arch.log1_481.dbf
ORA-00280: change 18499 for thread 1 is in sequence #481
Specify log: {<RET>=suggested | filename | AUTO | CANCEL}
Auto
Log applied
Media Recovery Complete
SVRMGR > alter tablespace tablespace_name2 online;
Statement processed.
Database recovery
This method is actually the easiest method, but it requires that the database be shut down to perform it. After restoring all the database files that were taken offline, close the database and issue the recover database command.
Once all the database files are restored, issued commands shown in Figure J.
SVRMGR > connect internal;
Connected.
SVRMGR > alter database close ;
Statement processed.
SVRMGR > recover database ;
ORA-00279: change 18499 generated at 02/21/98 11:49:56 needed for thread 1
ORA-00289: suggestion : /db/Oracle/admin/crash/arch/arch.log1_481.dbf
ORA-00280: change 18499 for thread 1 is in sequence #481
Specify log: {<RET>=suggested | filename | AUTO | CANCEL}
Auto
Log applied
Media Recovery Complete
SVRMGR > alter database open
Statement processed.
SVRMGR > connect internal;
Connected.
SVRMGR > select name, status from v$datafile
NAME
STATUS
--------------------------------------------------------------------------------
-------
/db/oracle/a/oradata/crash/system01.dbf
SYSTEM
/db/oracle/a/oradata/crash/rbs01.dbf
ONLINE
/db/oracle/a/oradata/crash/temp01.dbf
ONLINE
/db/oracle/a/oradata/crash/tools01.dbf
ONLINE
/db/oracle/a/oradata/crash/users01.dbf
ONLINE
/db/oracle/a/oradata/crash/test01.dbf
ONLINE
6 rows selected.
SVRMGR > select member, status from v$logfile
NAME
STATUS
--------------------------------------------------------------------------------
-------
/db/oracle/a/oradata/crash/system01.dbf
SYSTEM
/db/oracle/a/oradata/crash/rbs01.dbf
ONLINE
/db/oracle/a/oradata/crash/temp01.dbf
ONLINE
/db/oracle/a/oradata/crash/tools01.dbf
ONLINE
/db/oracle/a/oradata/crash/users01.dbf
ONLINE
/db/oracle/a/oradata/crash/test01.dbf
ONLINE
6 rows selected.
SVRMGR> select * from v$controlfile;
STATUS NAME
------- ------------------------------------------------------------------------
--------
/db/oracle/a/oradata/crash/control01.ctl
/db/oracle/b/oradata/crash/control02.ctl
/db/oracle/c/oradata/crash/control03.ctl
3 rows selected.
When we refer to a damaged log group, we mean that all members of a log group are damaged. If at least one member of a mirrored log group is intact, Oracle opens the database and simply put an error message in the alert log. However, if all members of a log group are damaged, the database will not open, and the error will look something like this:
ORA-00312: online log 2 thread 1: '/db/Oracle/b/oradata/crash/redocrash02.log'
ORA-00312: online log 2 thread 1: '/db/Oracle/a/oradata/crash/redocrash03.log'
SVRMGR > connect internal;
Connected.
SVRMGR > select group#, status from v$log;
---------- ----------------
1 INACTIVE
2 CURRENT
3 ACTIVE
3 rows selected.
Current
If a rollback segment is damaged, Oracle will complain when attempting to open the database. The error looks like the following:
Cannot open database if all rollback segments are not available.
If the preceding error is displayed when attempting to open the database, proceed to Step 19. If not, return to Step 10.
Because of the unique nature of damaged rollback segments, there are two choices for recovery. The first is to get the database open sooner, but that may leave it only partially functional for a longer period of time. The second choice takes a little longer to open the database, but once it is open it will not have data files that are needed for this rollback segment. Which is more important: getting even a partially functional database open as soon as possible, or not opening the database until all rollback segments are available? The latter is more prudent, but the former may be more appropriate to the environment.
SVRMGR > connect internal;
Connected.
SVRMGR > select TS#, name from v$datafile where status = 'OFFLINE' ;
NAME
--------------------------------------------------------------------------------
5 /db/oracle/a/oradata/crash/test01.dbf
1 row selected.
SVRMGR > connect internal;
Connected.
SVRMGR > select name from v$tablespace where TS# = '5' ;
NAME
--------------------------------------------------------------------------------
TEST
1 row selected.
Admittedly, the previous example was easy. There was only one data file that was offline, which made finding its tablespace pretty easy. What if there were multiple data files that were contained within multiple tablespaces? How do we know which one contains the rollback segment? Unfortunately, there is no way to be sure while the database is closed. That is why it is very helpful to put the rollback segments in dedicated tablespaces that have names that easily identify them as such. It's even more helpful if the data files are named something helpful as well. For example, create a separate tablespace called ROLLBACK_DATA, and call its data files rollback01.dbf, rollback02.dbf, etc. That way, anyone that finds himself in this scenario will know exactly which data files contain rollback data.
The rest of this step is simple. Restore any files that were taken offline, and use either the recover data file or recover tablespace commands to roll them forward in time. If there are only one or two damaged data files, it's probably quicker to use the recover data file command. If there are several damaged data files, especially if they are all in one tablespace, the recover tablespace command is probably easiest. Either way will work.
rollback_segments = (r01,r02,r03,r04)
ORA-00312: online log 2 thread 1: '/db/Oracle/b/oradata/crash/redocrash02.log'
ORA-00312: online log 2 thread 1: '/db/Oracle/a/oradata/crash/redocrash03.log'
This is the worst kind of failure to have because there will definitely be data loss. That is because the current online log is required to restart even a fully functioning database. The current control file knows about the current online log and will attempt to use it. The only way around that is to restore an older version of the control file. Unfortunately, you can't restore only the control file because the data files would then be more recent than the control file. The only remaining option is to restore the entire database.
SVRMGR > connect internal;
Connected.
SVRMGR > select name from v$datafile ;
SVRMGR > connect internal;
Connected.
SVRMGR > select member from v$logfile ;
After making a backup of the online redo log files, run the following command on a mounted, closed database:
SVRMGR > connect internal;
Connected.
SVRMGR > alter database open resetlogs
;
Statement processed.
Step 25: Is an Active Online Redo Log Damaged?
ORA-00312: online log 2 thread 1: '/db/Oracle/b/oradata/crash/redocrash02.log'
ORA-00312: online log 2 thread 1: '/db/Oracle/a/oradata/crash/redocrash03.log'
Remember that an ACTIVE log is one that is still needed for recovery. The reason that it is still needed is because a checkpoint has not flushed all changes from shared memory to disk. Once that happens, this log will no longer be needed.
The way to attempt to recover from the scenario in Step 25 is to perform a checkpoint. If it is successful, the database should open successfully. To perform a checkpoint, issue the following command on the mounted, closed database:
SVRMGR > connect internal;
Connected.
SVRMGR > alter system checkpoint
local ;
Statement processed.
ORA-00312: online log 2 thread 1: '/db/Oracle/b/oradata/crash/redocrash02.log'
ORA-00312: online log 2 thread 1: '/db/Oracle/a/oradata/crash/redocrash03.log'
In comparison, this one should be a breeze. An INACTIVE log is not needed by Oracle. If it is not needed, simply drop it and add another in its place.
SVRMGR > connect internal;
Connected.
SVRMGR > select member from v$logfile where GROUP# = '2 ;
/logs2redolog01.dbf
/logs3redolog01.dbf
To drop log group 2, issue the following command on a mounted, closed database:
SVRMGR > connect internal;
Connected.
SVRMGR > alter database drop logfile
group 2 ;
Statement processed.
SVRMGR > connect internal;
Connected.
SVRMGR > alter database add logfile
group 2 ('/logs1redolog01.dbf', '/logs2redolog01.dbf',
'/logs4redolog01.dbf') size 500K ;
Statement processed.
There was an option in Step 19 to comment out rollback segments from the initORACLE_SID.ora file. If that option was taken, there should be a line in that file that looks like the following:
rollback_segments = (r01,r02,r03,r04)
To check which rollback segments are offline, run the following command:
SEGMENT_NAME
------------------------------
USERS_RS
1 rows selected.
SVRMGR > connect internal;
Connected.
SVRMGR > alter rollback segment users_rs online ;
Statement processed.